Wichtig ist: ein Data Scientist muss nicht zwangsläufig von Anfang an die hochinnovativen Themen behandeln. Die allermeisten Innovationen bei der Datenanalyse und der Modellverbesserung entwickeln sich häufig zufällig, sei es durch aktuelle Projekte und deren Problemstellungen, das Kombinieren neuer Verfahren mit älteren Ansätzen oder plötzlich veränderter Rechenkapazitäten.
Andere innovative Ansätze sollten eher von anderen Geschäftsbereichen, wie dem Marketing, klar formuliert und in gemeinsamer Arbeit entwickelt werden.
Für eine fruchtbare Tätigkeit im Unternehmen gilt es, mindestens die folgenden Punkte zu beachten:
Ein Data Scientist sollte von Beginn an
- Einblick in das Tagesgeschäft (v.a. im Bereich BI und DWH) erhalten
- die fachlichen Anforderungen in seinem Bereich verstehen
- die Kontakte zur internen IT und zur Entscheider-Ebene aufbauen
- Technologien, die im Unternehmen genutzt werden, verstehen und mit dem eigenen Technologie-Wissen kombinieren
- Den Technologie-Markt regelmäßig beobachten und eigenes Wissen weiter anreichern
Je nach Branche, in der er tätig ist, sollte ein Data Scientist in der Lage sein, klassische Fragen aus dem BI-Bereich lösen zu können. Einige Beispiele dafür sind:
- … im Vertragskundengeschäft zu einer Verbesserung der Kundenbeziehung zu gelangen, z.B. indem unzufriedene Kunden statistisch identifiziert werden können, um ihnen im Anschluss Angebote oder Preisnachlässe zu gewähren und die Beziehung auf diese Weise zu verlängern (Classification). Ein Beispiel ist in Abb. 2 dargestellt.
- … den maximalen Gewinn aus dem Kunden herausholen, indem er mit den passendsten Angeboten aus dem eigenen Produkt-Stack konfrontiert wird, ohne ihn jedoch zu „überfrachten“ (Recommendation). Ein Beispiel ist in Abb. 3 dargestellt.
- … Kunden (oder Produkte) in sinnvolle Gruppen einteilen (Clustering), um aus den Gruppen bestimmte (und vorher noch unbekannte) Eigenschaften zu extrahieren, mit denen sich die „ähnlichsten“ anderen Produkte oder Kunden ermitteln lassen.
Ein Beispiel: Anstatt Marketingaktionen oder Werbemaßnahmen an Altersgruppen, Geschlecht oder weitere Einzelattribute anzupassen, teilt man den Kundenstamm in bspw. 20 Cluster auf und betrachtet die Kauf-Eigenschaften innerhalb jeden Clusters. Anschließend müssen lediglich 20 Pakete „geschnürt“ werden, die den meisten Kunden im Cluster zusagen. Dies Verfahren spart Arbeit und zeigt in der Regel gute Ergebnisse. - … Absatzprognosen und Auslastungsquoten auf Basis früherer Daten für die Zukunft berechnen.
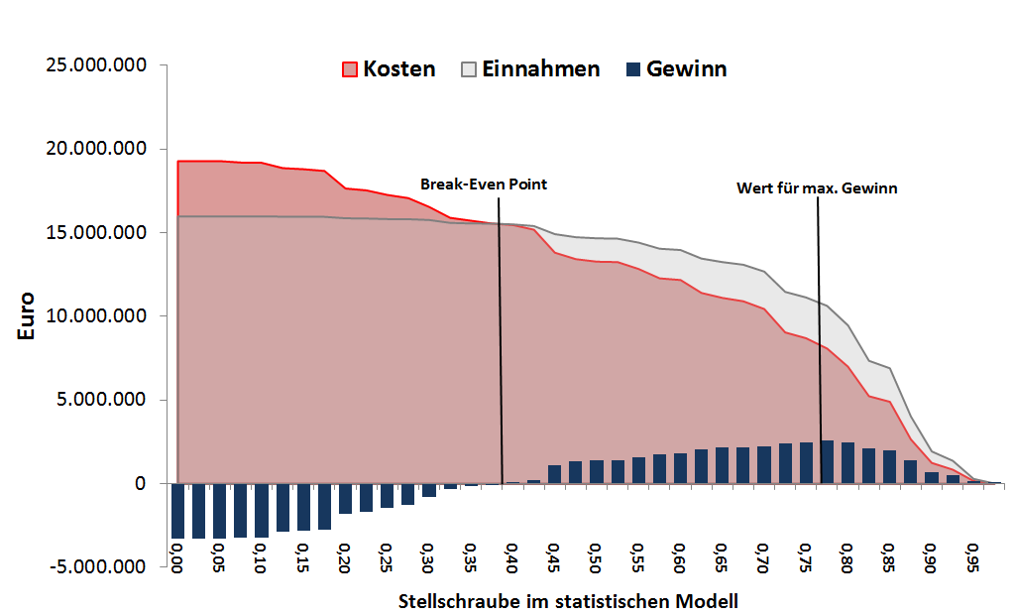
Abbildung 2: Modellergebnis für die Wirtschaftlichkeitsberechnung einer „Churn-Prediction“. Dabei wurde versucht, jene Kunden zu identifizieren, die mit einer großen Wahrscheinlichkeit demnächst kündigen werden. Diese gilt es im Vorfeld durch gezielte Preisnachlässe davon abzubringen. Je größer der Fehler bei der Identifizierung der richtigen Kunden (Model Precision), desto kleiner der zu erwartende Gewinn, weswegen dabei unterschiedliche Classifier getestet werden müssen, worauf anschließend noch ein Modell-Tuning folgt. Im Beispiel wurde mit einer Erfolgswahrscheinlichkeit von 25%, einer Rendite von 120 €/a pro Kunde und Rabatt von 60 €/a pro identifizierten Kunde gerechnet.

Abbildung 3: Der Recommender in der Theorie – Beispiel für Online-Bezahlcontent. Die „Ähnlichkeit“ zwischen Usern wird in der Regel in Form mathematischer Distanzmaße (Korrelation, Absolute Distances, Euclidean Distances) berechnet. Das Schaubild verdeutlicht folgende Logik: „Nimm jeden Content (z.B bezahlpflichtige Premium Angebote) ,den ich (Kunde) noch nicht kenne, schaue welchen davon die „mir ähnlichen User“ haben und schlage ihn mir in absteigender Reihenfolge, nach absolutem Auftreten unter den mir ähnlichsten Usern, vor.“ Bei anonymen Usern funktioniert die Logik ähnlich, nur dass ähnliche User erst nach einer bestimmten Anzahl beobachteter „Aktionen“ ermittelt werden können, während bei bekannten Usern diese Daten bereits existieren.
Innovative Tasks – Was darf der Data Scientist noch können
Bei der Bewältigung und Auswertung großer Datenmengen müssen statistische Berechnungen oftmals verteilt gerechnet werden. Dieser Bereich ist zwar auch im Bereich des Software Development mitangesiedelt, dennoch ist es sinnvoll, dass sich der Data Scientist mit diesen Technologien vertraut macht. Diese „Big Data“ –Themen sind vor allem dort wichtig, wo unstrukturierte Daten, wie Freitexte aus den sozialen Medien, Forum-Einträge oder ganze Blogs als Datengrundlage mit in die Modelle oder Auswertungen fließen. Theorie und Praxis des Text Minings als eine Form des Data Mining sind hierbei unabdingbar. Texte müssen ausgelesen, transformiert, auf Zusammenhänge, Tonalität etc. untersucht werden, um die dadurch gewonnenen Informationen in bestmöglicher Form für weitere Analysen zu nutzen, oder visuell aufzubereiten.
Um ein Beispiel zu zeigen, sind in Abb. 3 bis 5 die Tweets zu den zwei Produkten Samsung Galaxy S6 und Apples iPhone6 in raum-zeitlicher und themenspezifischer Dimension zu sehen. Die Beispiele sollen zeigen, wie mit relativ geringem Aufwand (im gezeigten Beispiel wurde eine individuelle Lösung in etwa 2 bis 3 Tagen konzipiert) eigene Produkte, aber auch jene der Konkurrenz, über einen längeren Zeitraum in den sozialen Medien beobachtet werden können. Dabei wird zu jedem Suchbegriff eine feste Anzahl an thematischen Unterteilungen a-priori festgelegt und per Clustering die gesamten Tweets, ihrer Ähnlichkeit zueinander entsprechend, zusammengefasst. Dies hat zum Ziel, all jene Begriffe in den Tweeds zu erkennen, die am häufigsten miteinander auftauchen. Dabei bedient man sich im Vorfeld häufig einer Normierungsvariante, die unwichtige Bestandteile wie Präpositionen, Artikel oder häufige Verben, die keinerlei Auskunft über den Inhalt geben, herausfiltert (Für Details siehe TF-IDF Normierung[1]). Diese Logik muss im Anschluss noch individuell angepasst werden, je nach individuellem Use Case. Auf diese Weise kann man nun themenspezifische Auswertungen machen, Stimmungen analysieren, Trends rechtzeitig erkennen, uvm.

Abbildung 4: Herkunft von ca. 60.000 Tweets, gesammelt zwischen 03.03.2015 und 05.03.2015, wovon sich rund zwei Drittel den Ländern zuordnen ließen. Das verbleibende Drittel wurde ausgeblendet, ebenso Länder mit weniger als 50 Einträgen.
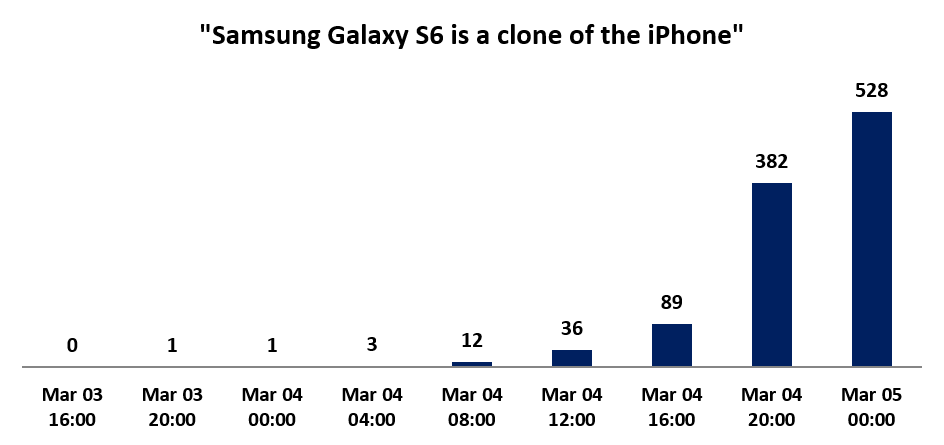
Abbildung 5: Entwicklung von Tweets, die dem Cluster „Samsung Galaxy S6 is a clone of the iPhone“ zugeordnet wurden. Die Benennung ergab sich aus den häufigsten Wörtern innerhalb des Cluster ‚clone‘, ‚iphone clone‘, ’samsung insist‘ (Datenbasis: 60.000 Tweets, gesammelt zwischen 03.03.2015 und 05.03.2015).
Bei allen Analysen ist es aber vor allem wichtig, zu erkennen, wer eigentlich Beiträge veröffentlicht. Durch Informationen, wie z.B. die Gesamt-Anzahl an Followern, kann man gezielt große Unternehmen herausfiltern, welche hier in unserem Fall Werte jenseits der 50.000 aufweisen. Auch eine Vielzahl an Spam-Tweets (Abb. 6) kann bis zu einem gewissen Grad aus den Daten durch intelligentes Filtern entfernt werden, etwa durch Erkennung ähnlich aufgebauter Tweets in kurzer zeitlicher Aufeinanderfolge. Auf diese Weise bekommt man also die „echten“ Meinungen von Usern zurück. Anschließend kann noch weiter nach Device (über welche App wurde Tweet abgesendet), Aktivität der User (Gesamtzahl an Tweets pro User) uvm. gefiltert werden, je nachdem, welche Fragestellung ein Unternehmen beantworten möchte.
Die Beispiele sollen lediglich demonstrieren, dass das Sammeln externer Daten durchaus Sinn machen kann, die Frage nach der tatsächlichen Rentabilität eines solchen Verfahrens und welche Datenquellen herangezogen werden sollen, muss sich jedes Unternehmen dennoch individuell selbst stellen.
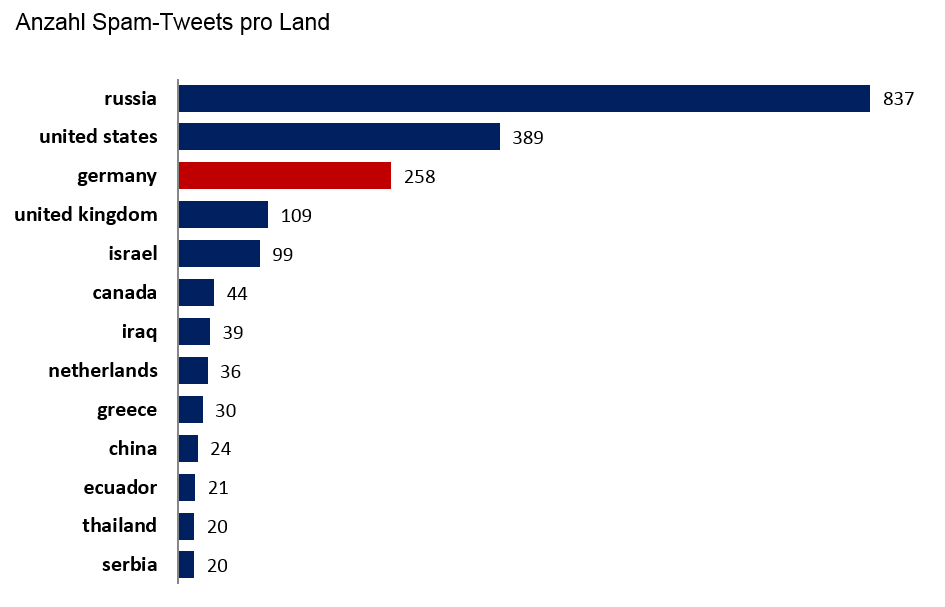
Abbildung 6: : Herkunft Tweets, die als Spam klassifiziert wurden, gesammelt zwischen 03.03.2015 und 05.03.2015. Länder mit weniger als 20 Einträgen wurden ausgeblendet. Die Spam-Tweets wurden anhand der Worthäufigkeiten klassischer Spambegriffe und durch das Vorkommen großer Teile des Textes in zeitnaher Aufeinanderfolge identifiziert.
Teil 3 folgt am Fr. 20.03.2015.
Damit nehmen wir an der Blogparade von SAS zum Thema Data Scientist teil.









 Dr. Andreas Rohleder ist Geschäftsführer der Rohleder.Management.Consulting GmbH. Für seine Forschung zum Operations Research wurde der Diplom-Kaufmann zum Dr. rer. pol. promoviert. Als Spezialist für Planung und Entscheidung mit quantitativen Methoden ist er Dozent der Rohleder.Business.Seminare. Er ist Lehrbeauftragter der Westfälischen Wilhelms-Universität Münster sowie registrierter PRINCE2® Pracitioner.
Dr. Andreas Rohleder ist Geschäftsführer der Rohleder.Management.Consulting GmbH. Für seine Forschung zum Operations Research wurde der Diplom-Kaufmann zum Dr. rer. pol. promoviert. Als Spezialist für Planung und Entscheidung mit quantitativen Methoden ist er Dozent der Rohleder.Business.Seminare. Er ist Lehrbeauftragter der Westfälischen Wilhelms-Universität Münster sowie registrierter PRINCE2® Pracitioner.